如何参与开发自定义Collector
Collector模块介绍

Collector模块整体结构可以分为四个主要部分,每个部分承担不同的职责:
-
Collector入口:这是Collector模块的运行入口,启动后会通过这个入口来执行采集任务。
-
collector-basic:该模块主要包含了基础的Collector实现,如HTTP、JDBC等通用协议的监控。这里的Collector通常不需要额外的专有依赖,能满足大多数基础监控需求。
-
collector-common:这个模块存放了一些通用的工具类和方法,比如公共的连接池、缓存机制等,其他模块可以复用这里的代码。
-
collector-xxx:这是为不同服务或协议的扩展Collector模块。例如,MongoDB、RocketMQ等特定服务的监控,往往需要引入它们的专有依赖,并在各自模块中进行开发。以下是MongoDB的依赖示例:
`<dependency>`
`<groupId>`org.mongodb`</groupId>`
`<artifactId>`mongodb-driver-sync`</artifactId>`
`</dependency>`
通过这种模块化设计,Collector可以轻松地扩展并适配多种监控场景。
新增Collector监控
接下来,我们将通过创建一个kafka-collector模块的实际案例来展示如何开发新的Collector。
1. 创建kafka-collector模块
首先,我们需要在项目中创建一个新的模块用于Kafka的监控,命名为kafka-collector。并在该模块中修改pom.xml文件。
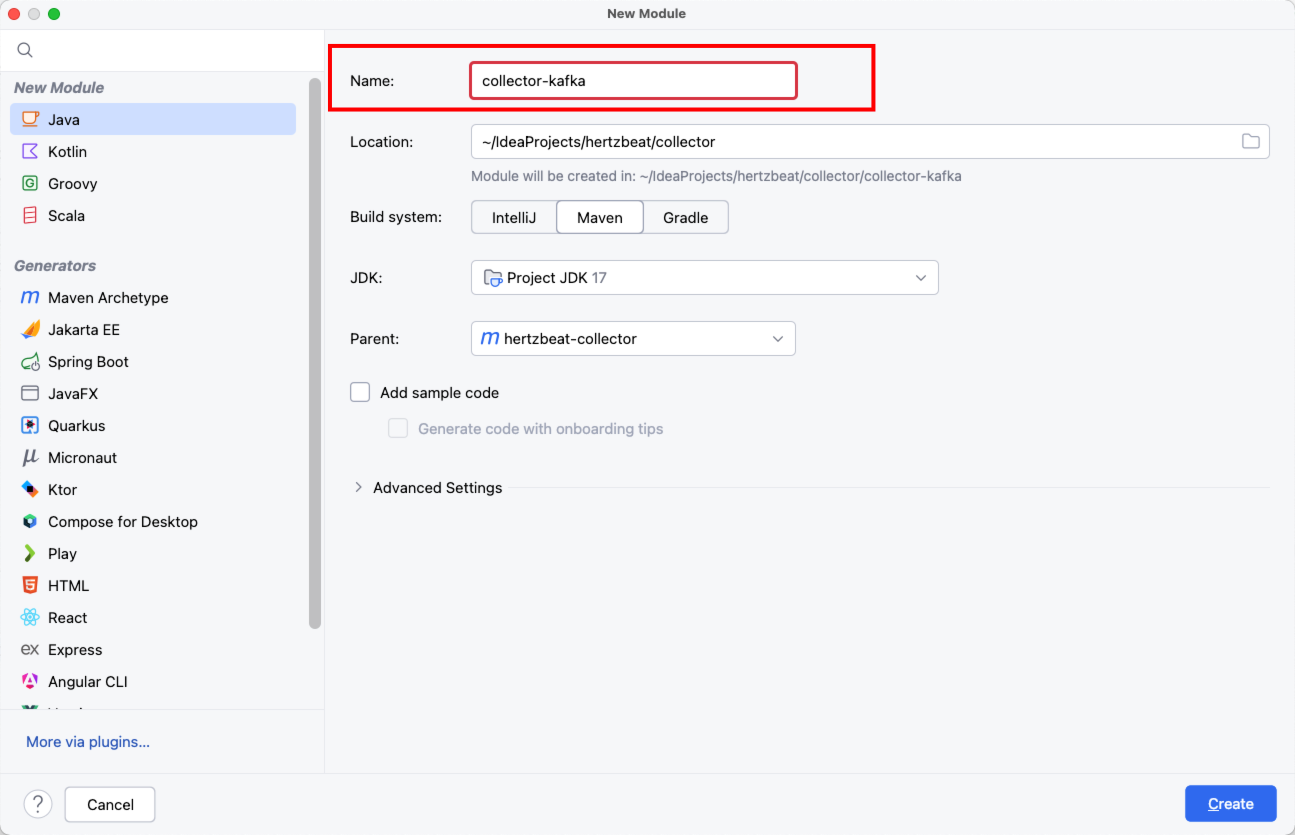
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
`<modelVersion>`4.0.0`</modelVersion>`
`<parent>`
`<groupId>`org.apache.hertzbeat`</groupId>`
`<artifactId>`hertzbeat-collector`</artifactId>`
`<version>`2.0-SNAPSHOT`</version>`
`</parent>`
`<artifactId>`hertzbeat-collector-kafka`</artifactId>`
`<name>`${project.artifactId}`</name>`
`<properties>`
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
`</properties>`
`<dependencies>`
`<dependency>`
`<groupId>`org.apache.hertzbeat`</groupId>`
`<artifactId>`hertzbeat-collector-common`</artifactId>`
`<scope>`provided`</scope>`
`</dependency>`
<!-- kafka -->
`<dependency>`
`<groupId>`org.apache.kafka`</groupId>`
`<artifactId>`kafka-clients`</artifactId>`
`</dependency>`
`</dependencies>`
`</project>`
此处需要注意的内容:
artifactId设为hertzbeat-collector-kafka,以保持命名一致性。dependencies中手动添加Kafka所需的依赖。
2. 新增Kafka协议类
为了让Collector模块能够处理Kafka的监控协议,我们需要创建一个KafkaProtocol类来��定义Kafka的连接参数。该类位于common/src/main/java/org/apache/hertzbeat/common/entity/job/protocol/KafkaProtocol.java。
package org.apache.hertzbeat.common.entity.job.protocol;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class KafkaProtocol {
/**
* IP地址或域名
*/
private String host;
/**
* 端口号
*/
private String port;
/**
* 超时时间
*/
private String timeout;
/**
* 指令
*/
private String command;
}
3. 在Metrics中添加Kafka支持
在common/src/main/java/org/apache/hertzbeat/common/entity/job/Metrics.java类中,加入Kafka协议的支持。
private KafkaProtocol kclient;
4. 新增常量
在DispatchConstants类中定义Kafka协议的常量。
String PROTOCOL_KAFKA = "kclient";
5. 新增Kafka连接类
KafkaConnect类用于管理Kafka Admin的连接逻辑。
package org.apache.hertzbeat.collector.collect.kafka;
import org.apache.hertzbeat.collector.collect.common.cache.AbstractConnection;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.KafkaAdminClient;
import java.util.Properties;
public class KafkaConnect extends AbstractConnection`<AdminClient>` {
private static AdminClient adminClient;
public KafkaConnect(String brokerList) {
Properties properties = new Properties();
properties.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
properties.put(AdminClientConfig.RETRIES_CONFIG, 3);
adminClient = KafkaAdminClient.create(properties);
}
@Override
public AdminClient getConnection() {
return adminClient;
}
@Override
public void closeConnection() throws Exception {
if (this.adminClient != null) {
this.adminClient.close();
}
}
public static synchronized AdminClient getAdminClient(String brokerList) {
if (adminClient == null) {
Properties properties = new Properties();
properties.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
adminClient = KafkaAdminClient.create(properties);
}
return adminClient;
}
}
6. 实现Kafka采集类
继承AbstractCollect类,并在其中实现具体的数据采集逻辑。这里不对具体逻辑进行介绍了。
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hertzbeat.collector.collect.kafka;
import lombok.extern.slf4j.Slf4j;
import org.apache.hertzbeat.collector.collect.AbstractCollect;
import org.apache.hertzbeat.collector.dispatch.DispatchConstants;
import org.apache.hertzbeat.common.entity.job.Metrics;
import org.apache.hertzbeat.common.entity.job.protocol.KafkaProtocol;
import org.apache.hertzbeat.common.entity.message.CollectRep;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.DescribeTopicsResult;
import org.apache.kafka.clients.admin.ListTopicsOptions;
import org.apache.kafka.clients.admin.ListTopicsResult;
import org.apache.kafka.clients.admin.OffsetSpec;
import org.apache.kafka.clients.admin.TopicDescription;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.TopicPartitionInfo;
import org.springframework.util.Assert;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
@Slf4j
public class KafkaCollectImpl extends AbstractCollect {
@Override
public void preCheck(Metrics metrics) throws IllegalArgumentException {
KafkaProtocol kafkaProtocol = metrics.getKclient();
// Ensure that metrics and kafkaProtocol are not null
Assert.isTrue(metrics != null && kafkaProtocol != null, "Kafka collect must have kafkaProtocol params");
// Ensure that host and port are not empty
Assert.hasText(kafkaProtocol.getHost(), "Kafka Protocol host is required.");
Assert.hasText(kafkaProtocol.getPort(), "Kafka Protocol port is required.");
}
@Override
public void collect(CollectRep.MetricsData.Builder builder, long monitorId, String app, Metrics metrics) {
try {
KafkaProtocol kafkaProtocol = metrics.getKclient();
String command = kafkaProtocol.getCommand();
boolean isKafkaCommand = SupportedCommand.isKafkaCommand(command);
if (!isKafkaCommand) {
log.error("Unsupported command: {}", command);
return;
}
// Create AdminClient with the provided host and port
AdminClient adminClient = KafkaConnect.getAdminClient(kafkaProtocol.getHost() + ":" + kafkaProtocol.getPort());
// Execute the appropriate collection method based on the command
switch (SupportedCommand.fromCommand(command)) {
case TOPIC_DESCRIBE:
collectTopicDescribe(builder, adminClient);
break;
case TOPIC_LIST:
collectTopicList(builder, adminClient);
break;
case TOPIC_OFFSET:
collectTopicOffset(builder, adminClient);
break;
default:
log.error("Unsupported command: {}", command);
break;
}
} catch (InterruptedException | ExecutionException e) {
log.error("Kafka collect error", e);
}
}
/**
* Collect the earliest and latest offsets for each topic
*
* @param builder The MetricsData builder
* @param adminClient The AdminClient
* @throws InterruptedException If the thread is interrupted
* @throws ExecutionException If an error occurs during execution
*/
private void collectTopicOffset(CollectRep.MetricsData.Builder builder, AdminClient adminClient) throws InterruptedException, ExecutionException {
ListTopicsResult listTopicsResult = adminClient.listTopics(new ListTopicsOptions().listInternal(true));
Set`<String>` names = listTopicsResult.names().get();
names.forEach(name -> {
try {
Map<String, TopicDescription> map = adminClient.describeTopics(Collections.singleton(name)).all().get(3L, TimeUnit.SECONDS);
map.forEach((key, value) -> value.partitions().forEach(info -> extractedOffset(builder, adminClient, name, value, info)));
} catch (TimeoutException | InterruptedException | ExecutionException e) {
log.warn("Topic {} get offset fail", name);
}
});
}
private void extractedOffset(CollectRep.MetricsData.Builder builder, AdminClient adminClient, String name, TopicDescription value, TopicPartitionInfo info) {
try {
TopicPartition topicPartition = new TopicPartition(value.name(), info.partition());
long earliestOffset = getEarliestOffset(adminClient, topicPartition);
long latestOffset = getLatestOffset(adminClient, topicPartition);
CollectRep.ValueRow.Builder valueRowBuilder = CollectRep.ValueRow.newBuilder();
valueRowBuilder.addColumns(value.name());
valueRowBuilder.addColumns(String.valueOf(info.partition()));
valueRowBuilder.addColumns(String.valueOf(earliestOffset));
valueRowBuilder.addColumns(String.valueOf(latestOffset));
builder.addValues(valueRowBuilder.build());
} catch (TimeoutException | InterruptedException | ExecutionException e) {
log.warn("Topic {} get offset fail", name);
}
}
/**
* Get the earliest offset for a given topic partition
*
* @param adminClient The AdminClient
* @param topicPartition The TopicPartition
* @return The earliest offset
*/
private long getEarliestOffset(AdminClient adminClient, TopicPartition topicPartition)
throws InterruptedException, ExecutionException, TimeoutException {
return adminClient
.listOffsets(Collections.singletonMap(topicPartition, OffsetSpec.earliest()))
.all()
.get(3L, TimeUnit.SECONDS)
.get(topicPartition)
.offset();
}
/**
* Get the latest offset for a given topic partition
*
* @param adminClient The AdminClient
* @param topicPartition The TopicPartition
* @return The latest offset
*/
private long getLatestOffset(AdminClient adminClient, TopicPartition topicPartition)
throws InterruptedException, ExecutionException, TimeoutException {
return adminClient
.listOffsets(Collections.singletonMap(topicPartition, OffsetSpec.latest()))
.all()
.get(3L, TimeUnit.SECONDS)
.get(topicPartition)
.offset();
}
/**
* Collect the list of topics
*
* @param builder The MetricsData builder
* @param adminClient The AdminClient
*/
private static void collectTopicList(CollectRep.MetricsData.Builder builder, AdminClient adminClient) throws InterruptedException, ExecutionException {
ListTopicsOptions options = new ListTopicsOptions().listInternal(true);
Set`<String>` names = adminClient.listTopics(options).names().get();
names.forEach(name -> {
CollectRep.ValueRow valueRow = CollectRep.ValueRow.newBuilder().addColumns(name).build();
builder.addValues(valueRow);
});
}
/**
* Collect the description of each topic
*
* @param builder The MetricsData builder
* @param adminClient The AdminClient
*/
private static void collectTopicDescribe(CollectRep.MetricsData.Builder builder, AdminClient adminClient) throws InterruptedException, ExecutionException {
ListTopicsOptions options = new ListTopicsOptions();
options.listInternal(true);
ListTopicsResult listTopicsResult = adminClient.listTopics(options);
Set`<String>` names = listTopicsResult.names().get();
DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(names);
Map<String, TopicDescription> map = describeTopicsResult.all().get();
map.forEach((key, value) -> {
List`<TopicPartitionInfo>` listp = value.partitions();
listp.forEach(info -> {
CollectRep.ValueRow.Builder valueRowBuilder = CollectRep.ValueRow.newBuilder();
valueRowBuilder.addColumns(value.name());
valueRowBuilder.addColumns(String.valueOf(value.partitions().size()));
valueRowBuilder.addColumns(String.valueOf(info.partition()));
valueRowBuilder.addColumns(info.leader().host());
valueRowBuilder.addColumns(String.valueOf(info.leader().port()));
valueRowBuilder.addColumns(String.valueOf(info.replicas().size()));
valueRowBuilder.addColumns(String.valueOf(info.replicas()));
builder.addValues(valueRowBuilder.build());
});
});
}
@Override
public String supportProtocol() {
return DispatchConstants.PROTOCOL_KAFKA;
}
}
7. 配置SPI服务文件
在collector/collector/src/main/resources/META-INF/services/org.apache.hertzbeat.collector.collect.AbstractCollect文件中,添加KafkaCollectImpl类。
...
org.apache.hertzbeat.collector.collect.kafka.KafkaCollectImpl
8. 在Collector模块添加Kafka依赖
最后一步是在collector/collector/pom.xml中添加kafka-collector模块的依赖:
`<dependency>`
`<groupId>`org.apache.hertzbeat`</groupId>`
`<artifactId>`hertzbeat-collector-kafka`</artifactId>`
`<version>`${hertzbeat.version}`</version>`
`</dependency>`
通过以上步骤,我们就完成了一个Kafka Collector的开发,从协议定义到最终的SPI配置和依赖管理,完整的扩展了一个Kafka监控模块。
添加配置解析文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# The monitoring type category:service-application service monitoring db-database monitoring custom-custom monitoring os-operating system monitoring
category: mid
# The monitoring type eg: linux windows tomcat mysql aws...
app: kafka_client
# The monitoring i18n name
name:
zh-CN: Kafka消息系统(客户端)
en-US: Kafka Message(Client)
# The description and help of this monitoring type
help:
zh-CN: HertzBeat 使用 <a href="https://hertzbeat.apache.org/docs/advanced/extend-jmx">Kafka Admin Client`</a>` 对 Kafka 的通用指标进行采集监控。`</span>`
en-US: HertzBeat uses <a href='https://hertzbeat.apache.org/docs/advanced/extend-jmx'>Kafka Admin Client`</a>` to monitoring kafka general metrics. `</span>`
zh-TW: HertzBeat 使用 <a href="https://hertzbeat.apache.org/docs/advanced/extend-jmx">Kafka Admin Client`</a>` 對 Kafka 的通用指標進行采集監控。`</span>`
helpLink:
zh-CN: https://hertzbeat.apache.org/zh-cn/docs/help/kafka_client
en-US: https://hertzbeat.apache.org/docs/help/kafka_client
# Input params define for monitoring(render web ui by the definition)
params:
# field-param field key
- field: host
# name-param field display i18n name
name:
zh-CN: 目标Host
en-US: Target Host
# type-param field type(most mapping the html input type)
type: host
# required-true or false
required: true
- field: port
name:
zh-CN: 端口
en-US: Port
type: number
# when type is number, range is required
range: '[0,65535]'
required: true
defaultValue: 9092
# collect metrics config list
metrics:
# metrics - server_info
- name: topic_list
i18n:
zh-CN: 主题列表
en-US: Topic List
# metrics scheduling priority(0->127)->(high->low), metrics with the same priority will be scheduled in parallel
# priority 0's metrics is availability metrics, it will be scheduled first, only availability metrics collect success will the scheduling continue
priority: 0
# collect metrics content
fields:
# field-metric name, type-metric type(0-number,1-string), unit-metric unit('%','ms','MB'), label-whether it is a metrics label field
- field: TopicName
type: 1
i18n:
zh-CN: 主题名称
en-US: Topic Name
# the protocol used for monitoring, eg: sql, ssh, http, telnet, wmi, snmp, sdk
protocol: kclient
# the config content when protocol is jmx
kclient:
host: ^_^host^_^
port: ^_^port^_^
command: topic-list
- name: topic_detail
i18n:
zh-CN: 主题详细信息
en-US: Topic Detail Info
# metrics scheduling priority(0->127)->(high->low), metrics with the same priority will be scheduled in parallel
# priority 0's metrics is availability metrics, it will be scheduled first, only availability metrics collect success will the scheduling continue
priority: 0
# collect metrics content
fields:
# field-metric name, type-metric type(0-number,1-string), unit-metric unit('%','ms','MB'), label-whether it is a metrics label field
- field: TopicName
type: 1
i18n:
zh-CN: 主题名称
en-US: Topic Name
- field: PartitionNum
type: 1
i18n:
zh-CN: 分区数量
en-US: Partition Num
- field: PartitionLeader
type: 1
i18n:
zh-CN: 分区领导者
en-US: Partition Leader
- field: BrokerHost
type: 1
i18n:
zh-CN: Broker主�机
en-US: Broker Host
- field: BrokerPort
type: 1
i18n:
zh-CN: Broker端口
en-US: Broker Port
- field: ReplicationFactorSize
type: 1
i18n:
zh-CN: 复制因子大小
en-US: Replication Factor Size
- field: ReplicationFactor
type: 1
i18n:
zh-CN: 复制因子
en-US: Replication Factor
# the protocol used for monitoring, eg: sql, ssh, http, telnet, wmi, snmp, sdk
protocol: kclient
# the config content when protocol is jmx
kclient:
host: ^_^host^_^
port: ^_^port^_^
command: topic-describe
- name: topic_offset
i18n:
zh-CN: 主题偏移量
en-US: Topic Offset
# metrics scheduling priority(0->127)->(high->low), metrics with the same priority will be scheduled in parallel
# priority 0's metrics is availability metrics, it will be scheduled first, only availability metrics collect success will the scheduling continue
priority: 0
# collect metrics content
fields:
# field-metric name, type-metric type(0-number,1-string), unit-metric unit('%','ms','MB'), label-whether it is a metrics label field
- field: TopicName
type: 1
i18n:
zh-CN: 主题名称
en-US: Topic Name
- field: PartitionNum
type: 1
i18n:
zh-CN: 分区数量
en-US: Partition Num
- field: earliest
type: 0
i18n:
zh-CN: 最早偏移量
en-US: Earliest Offset
- field: latest
type: 0
i18n:
zh-CN: 最新偏移量
en-US: Latest Offset
# the protocol used for monitoring, eg: sql, ssh, http, telnet, wmi, snmp, sdk
protocol: kclient
# the config content when protocol is jmx
kclient:
host: ^_^host^_^
port: ^_^port^_^
command: topic-offset
到这里自定义开发collector就完成了,启动服务就可以按照正常逻辑开始监控指标。
开发调试
本地启动manager模块时,如果提示我们添加的监控找不到类,将依赖再添加到manager模块下。
注意:打包提交代码时,不需要将manager模块下的依赖提交。
<!-- collector-kafka -->
`<dependency>`
`<groupId>`org.apache.hertzbeat`</groupId>`
`<artifactId>`hertzbeat-collector-kafka`</artifactId>`
`<version>`${hertzbeat.version}`</version>`
`</dependency>`